전통적으로 추천 시스템은 클러스터링, KNN 및 행렬 분해를 기반으로 합니다.
하지만 최근 딥러닝이 모든 분야에 적용되기 시작했고 추천 시스템도 예외는 아니다.
암호: https://www.kaggle.com/code/mmvv11/deep-learning-based-recommender-systems
참조 출처: https://www.kaggle.com/code/jamesloy/deep-learning-based-recommender-systems
추천 시스템에서 암시적 피드백과 명시적 피드백의 차이점 이해
모델을 본격적으로 구축하기 전에 추천 시스템에서 암시적 피드백과 명시적 피드백의 차이점을 이해하는 것이 매우 중요합니다.
그리고 현대 추천 시스템이 암시적 피드백을 기반으로 모델을 구축하는 이유를 이해해야 합니다.
우선 명시적인 피드백입니다.
이는 매우 명확한 피드백을 의미합니다.
예를 들어 배민에서는 고객이 매장에 별점을 주는 것과 같은 것을 명확한 피드백이라고 합니다.
또는 YouTube에서 좋아요 또는 싫어요.
물론 이런 피드백은 직관적이고 좋지만 매우 드물다는 특징이 있다.
현실적으로 유튜브 영상을 하루에 100개 보면 좋아요가 5개가 될까요?
다음은 암시적 피드백입니다.
이는 암시적 피드백을 의미합니다.
예를 들어 유튜브 영상을 시청하는 행위는 개인의 취향을 알 수 있는 단서로 볼 수 있다.
이 암시적 피드백의 장점은 데이터 양이 충분하다는 것입니다.
인터넷에서 클릭하는 모든 것이 데이터가 될 수 있기 때문입니다.
그러나 이것은 또한 단점이 있습니다.
데이터가 존재한다고 해서 모든 사람이 데이터를 좋아한다고 가정할 수 없다는 의미는 아닙니다.
그렇다면 부정적인 것이 무엇인지 어떻게 알아낼 수 있습니까?
다양한 방법이 있지만 그 중 하나가 네거티브 샘플링이라는 방법입니다.
데이터 전처리
Movielens-20m 데이터 세트를 활용합니다.
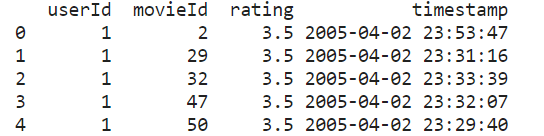
영화 렌즈 데이터는 위와 같습니다.
“User Index, Movie Index, Rating, Time”과 같은 열이 있습니다.
훈련-테스트 분할

시간을 나타내는 타임스탬프 열을 사용하여 훈련 테스트 세트를 분할합니다.
여기 일회성 방법을 적용하십시오.
즉, 가장 최근에 본 동영상이 테스트 데이터로 사용됩니다.
즉, Avatar, John Carter, Interstellar에 대한 모델을 훈련시키고 top-k 추천을 한 다음 top-k 안에 Guardians of the Galaxy가 있는지 확인합니다.
Movie Lens의 명시적 데이터를 암시적 데이터로 변경
MovieLens에 존재하는 등급 열은 실제로 사용자가 영화에 부여한 등급이므로 노골적인 피드백이라고 할 수 있습니다.
그러나 암시적 데이터를 사용하여 권장 사항을 만드는 것이 목적입니다.
따라서 등급이 있으면 사용자와 영화 사이에 인터랙션이 있다고 가정하고 1로 설정합니다.
반대로 등급이 없는 영화의 경우 인터랙션이 없다고 가정하고 0으로 설정합니다.
이러한 방식으로 등급의 명시적 데이터가 암시적 데이터로 변경됩니다.
(물론 이건 설정에 따라 다르겠죠. 예를 들어 평점이 3이상이면 1, 아니면 0. 이런 식으로 긍부정을 나눕니다. 그리고 판단해야 할 문제라고 생각합니다.)
이와 같이 암시적 데이터로 전환했기 때문에 추천 모델의 목적은 사용자가 영화에 부여하는 평점을 예측하는 것이 아닙니다.
이제 사용자와 영화 사이에 어떤 상호 작용이 있습니까? 이것을 확률로 예측하는 문제다.
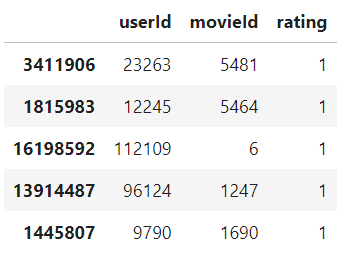
이런 식으로 데이터가 존재한다면 인터랙션이 존재한다고 할 수 있으니 등급 열을 1로 변경하면 됩니다.
네거티브 샘플링(4:1)
그러나 위와 같이 모든 데이터가 1개만 있으면 모델이 학습할 수 없습니다.
모델이 학습하려면 데이터가 0이어야 합니다.
따라서 네거티브 샘플링이 수행됩니다.
기존 사용자가 임의로 선택한 영화와 상호 작용한 적이 없는 경우 데이터를 0으로 추가하는 것입니다.
그리고 4:1 비율로 설정합니다. (물론 네거티브 샘플레이트를 실험적으로 바꿔가며 실험해보는 것도 좋다.)
예를 들어 3번 사용자가 1번과 4번 두 편의 영화를 본 경우 8번의 음성 샘플이 수행됩니다.
신경 협력 필터링(NCF) 모델
딥러닝 기반 추천 모델 신경 협력 필터링 사용.
임베딩 이해
임베딩은 고차원 데이터를 저차원 벡터로 변환하는 것입니다.
예를 들어, 현재 많은 데이터가 있습니다.
이를 바탕으로 사용자의 선호도를 액션을 좋아하는지 로맨스를 좋아하는지 2차원으로만 표현하는 것이 목적이다.
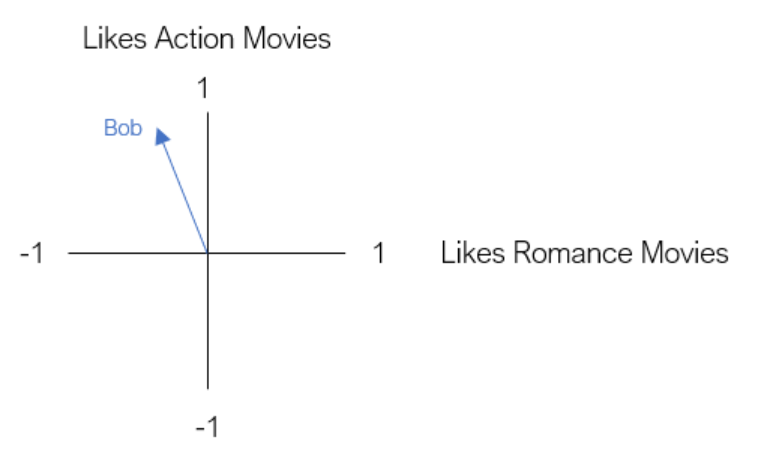
Bob이라는 사용자가 있다고 가정하고, 이 사람이 액션 영화를 좋아하지만 로맨스 영화는 그다지 좋아하지 않는다는 임베딩을 얻었다고 가정하면 그의 선호도는 위의 그림과 같이 표현될 수 있습니다.
임베딩입니다.
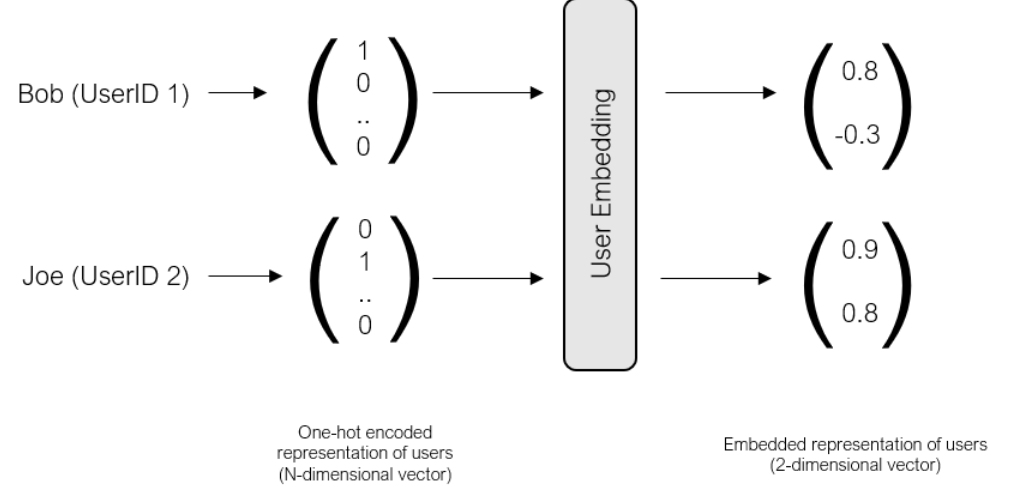
사실 사용자가 많은 고차원 벡터가 있겠지만 각 사용자는 원-핫 벡터로 표현되고 임베딩을 통해 2차원 임베디드 벡터로 표현된다.
예제에서는 직관적인 이해를 위해 2D라고 하는데, 이는 설정에 따라 다릅니다.
차원이 커질수록 용량이 늘어나 사용자가 자신의 취향을 보다 구체적으로 표현할 수 있습니다.
실험에서는 8차원을 사용합니다.
NCF 모델 구조
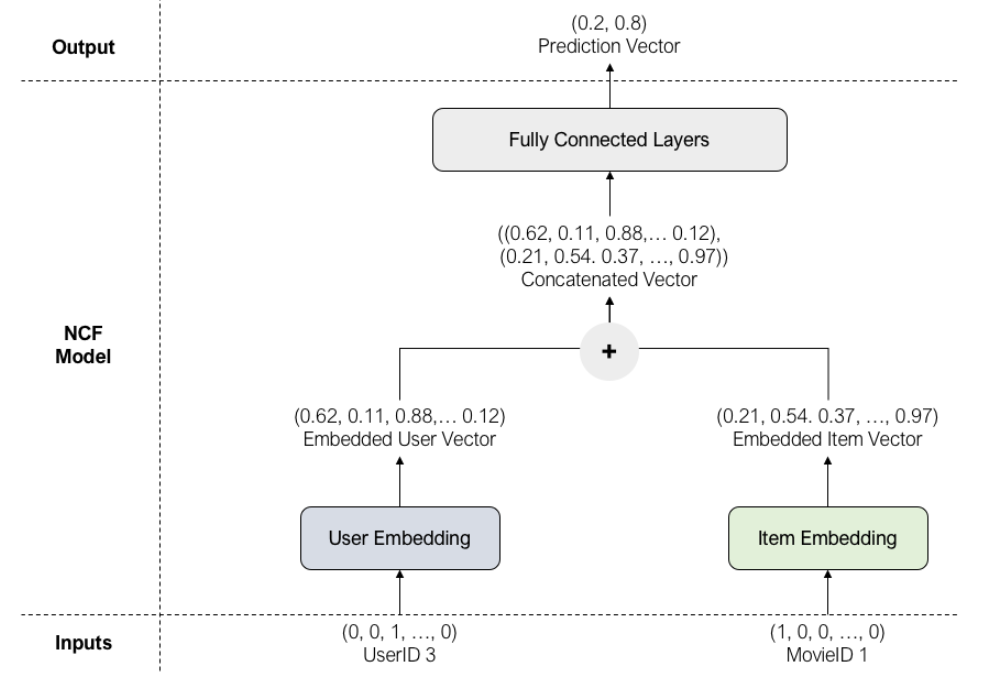
이러한 데이터가 있다고 가정하고 모델 아키텍처를 이해하려고 노력하십시오.
데이터: 사용자 #3은 영화 #1과 상호 작용했습니다.
– 사용자 3번은 원-핫 벡터로 표현되며 임베딩 레이어를 거쳐 8차원 벡터로 표현된다.
– 1번 항목도 같은 논리를 거친다.
– 사용자 임베딩과 항목 임베딩을 연결하고 FC 레이어를 통해 전달합니다.
– 마지막으로 결과는 시그모이드를 통해 출력된다.
– 이 예에서는 0.8의 결과를 얻습니다. 즉, 결과는 상호 작용할 확률이 80%라는 것입니다.
모델 평가 – 적중률
추천 시스템에서 단순히 Accuracy 또는 RMSE를 적용하여 모델을 평가하는 것은 공정하지 않습니다.
정확도는 분류와 같은 문제에 적합하기 때문입니다. 모델이 분류를 잘했다면 잘했다고 말할 수 있습니다.
RMSE의 경우 회귀와 같은 문제에 대해 합리적입니다. 모델이 실제 데이터와 얼마나 떨어져 있는지 칭찬할 수 있고, 최대한 근사하면 잘한 것입니다.
그러나 추천 시스템의 경우 이러한 메트릭이 적합하지 않습니다.
Netflix는 수많은 영화를 추천합니다.
그리고 그 중 하나를 클릭하고 재미있게 즐기면 좋은 추천이라고 생각하겠습니다.
이것이 추천 시스템에 적절한 메트릭이 필요한 이유입니다.
추천 시스템은 사용자가 모든 항목과 상호 작용하도록 하는 것을 목표로 하지 않습니다.
권장 사항 중 하나 이상이 작동하면 권장 사항이 잘 수행된 것입니다.
따라서 추천 시스템을 다음과 같이 평가합니다.
- 각 사용자에 대해 사용자가 이전에 본 적이 없는 99개의 영화를 무작위로 선택합니다.
- 테스트 데이터로 존재하는 하나의 동영상을 99개의 동영상에 삽입하여 데이터를 구성합니다.
- 총 100편의 영화를 NCF 모델에 넣어 사용자와 상호 작용할 확률을 찾습니다.
- 확률이 가장 높은 10개의 영화를 선택합니다.
- Top 10 추천 영화에 테스트 데이터가 포함되어 있는지 확인하십시오. 포함된다면 추천은 히트! 그게했다.
- 우리는 모든 사용자를 위해 이 과정을 거칩니다.
- 조회수 평균은 조회수를 총 사용자 수로 나누어 계산합니다. 적중률로 모델의 성능을 평가합니다.
이상 NCF를 이용한 추천에 대한 설명이었습니다.
NCF는 사용자 및 항목 임베딩을 활용하고 이를 신경망에 넣어 추천하는 간단하고 강력한 모델입니다.